归并排序
介绍
归并排序 (Merge−sort) 是利用归并的思想实现的排序方法,该算法采用经典的分治 (divide−and−conquer) 策略。
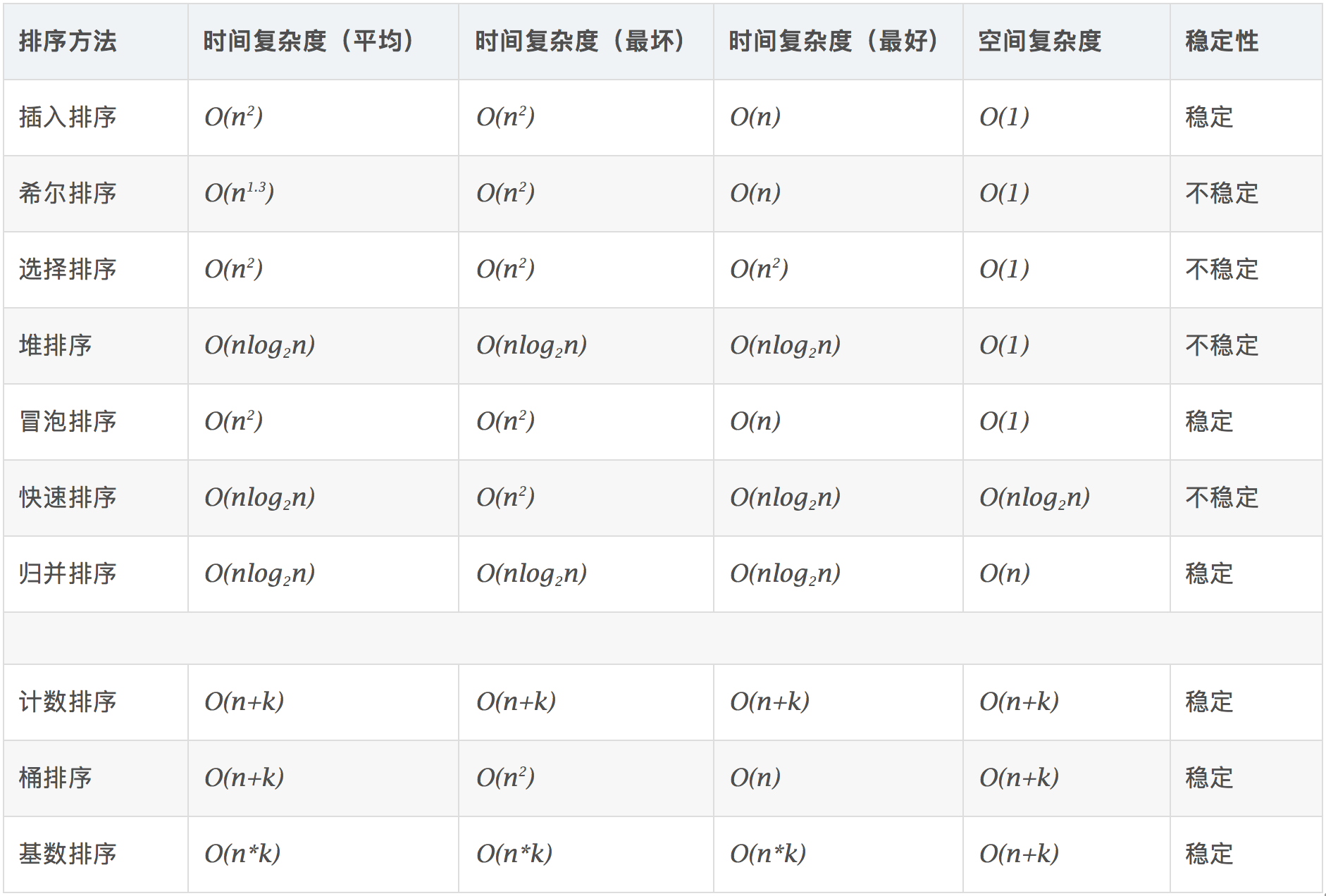
如图,具体来说,归并排序在排序的时候,会把一段数组拆分成不同的小数组(临界时只有一个元素),并在合并时排序。
复杂度/稳定性
时间复杂度
以上图代码为例,此时 n=8 ,可以看到,归并排序的分段是以下标二分的办法.
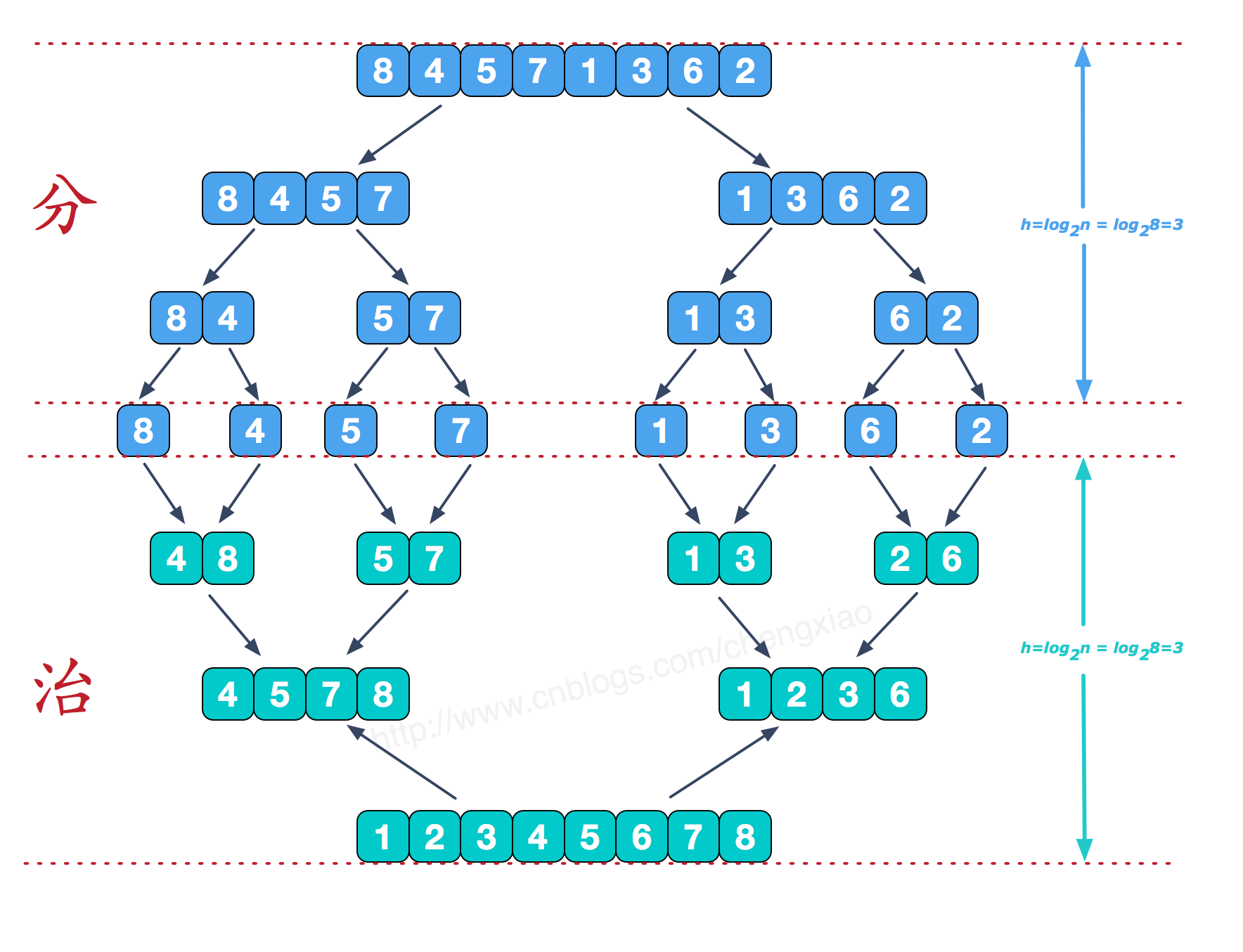
如下图,具体来看,对于分出的每两段数组合并的时候,每一层都会比较 n 次,总共有 log2n 层,时间复杂度为 O(nlog2n)
稳定性
每两段数组都是相邻的,相同的数合并时相对位置不会变化,因此它是稳定的。
代码实现
以下是c++实现,请参考注释理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| const int N = 1e4+5;
int n, tmp[N], a[N];
void fsort(int l, int r){
if(l >= r) return ;
int mid = (l+r)/2;
fsort(l, mid);
fsort(mid+1, r);
int i = l, j = mid+1, k = l;
while(i <= mid && j <= r){
if(a[i] <= a[j]){
tmp[k] = a[i];
i++;
k++;
}
else{
tmp[k] = a[j];
j++;
k++;
}
}
while(i<=mid){
tmp[k]=a[i];
i++;
k++;
}
while(j<=r){
tmp[k]=a[j];
j++;
k++;
}
for(int i = l; i <= r; i++)
a[i] = tmp[i];
}
signed main(){
fsort(1, n);
return 0;
}
|
快速排序
介绍
快速排序 (Quick−sort) 利用二分思想,完成数列的排序操作。
快速排序通过在待排序序列中选取基准值,再将数列调整为以基准值位置为界,一侧比基准值小,另一侧则比基准值大,然后递归两侧执行同样操作,即可完成排序。
如图1:
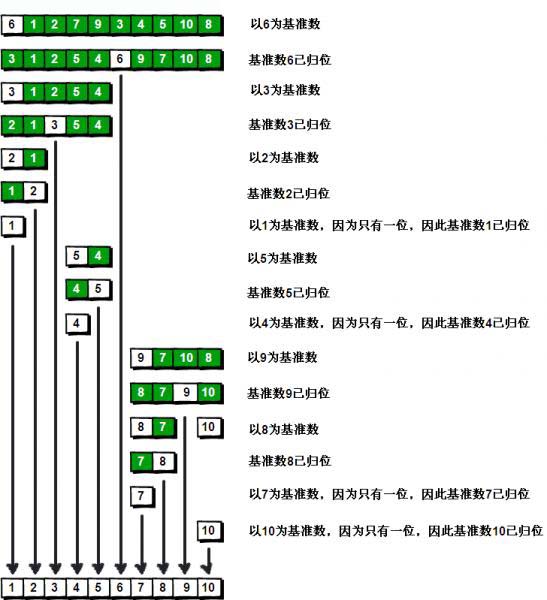
而具体到每次操作,可以参考下面这张图2:

复杂度/稳定性分析
时间复杂度
最好情况下,每次划分可以均衡,类比归并排序,每一层排 n 个数,共有 log2n 层,时间复杂度为 O(nlog2n)
最坏情况下:基准值选取最值,每次划分会出现空序列,需要划分 n 次,即共有 n 层,时间复杂度为 O(n2)
同理,如果基准值失去随机性,快速排序的时间复杂度也会退化到 O(n2)
稳定性
快速排序每次按照基准值分类的时候,如上图,若两个元素数值相等,在 i 、 j 互换的过程中,相对位置会发生变化,所以不稳定。
代码实现
以下是c++实现,请参考注释理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| const int N = 1e4+5;
int n, a[N];
void quicksort(int l, int r){
if(l >= r) return ;
int t = a[l];
int i = l, j = r;
while(i < j){
while( a[j] > t ) j--;
while( a[i] <= t && i<j) i++;
if(i < j) swap(a[i], a[j]);
}
swap(a[l],a[i]);
quicksort(l,i-1);
quicksort(i+1,r);
}
signed main(){
quicksort(1, n);
return 0;
}
|
堆排序
堆排序 (Heap−sort) 是借助堆这种数据结构完成的排序,思路类似于选择排序。
它和选择排序最大的不同是使用了树这一数据结构,把选择排序效率低下的一个个元素遍历的查找改为在树中查找。
前置芝士:堆
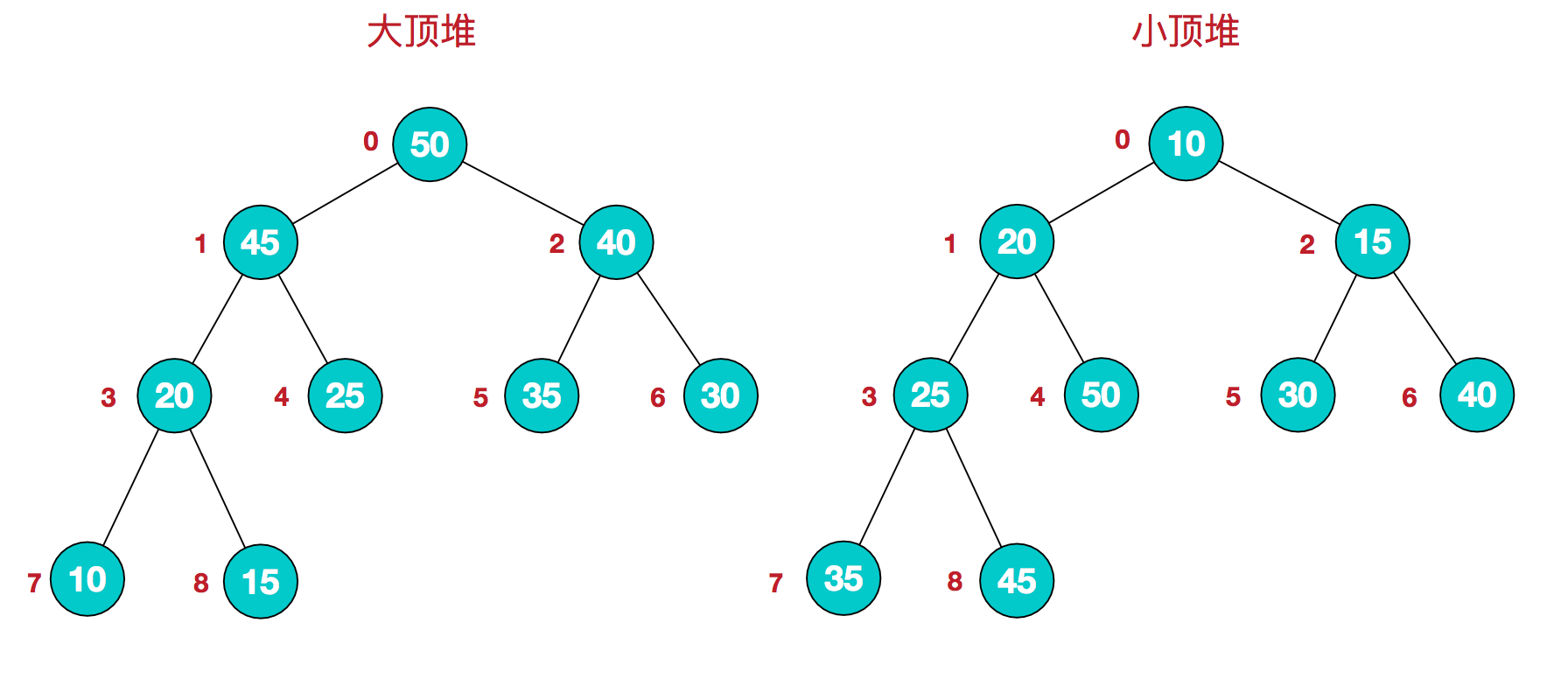
如图,堆是一种特殊的完全二叉树,分为大顶堆与小顶堆两种:
- 大顶堆: 完全二叉树中任一非叶子结点的值都大于等于其子结点的值。
- 小顶堆: 完全二叉树中任一非叶子结点的值都小于等于其子结点的值。
介绍
选择排序的原理还是很好懂的,所以跳过这一块(类比即可),着重讲如何用堆查找元素。
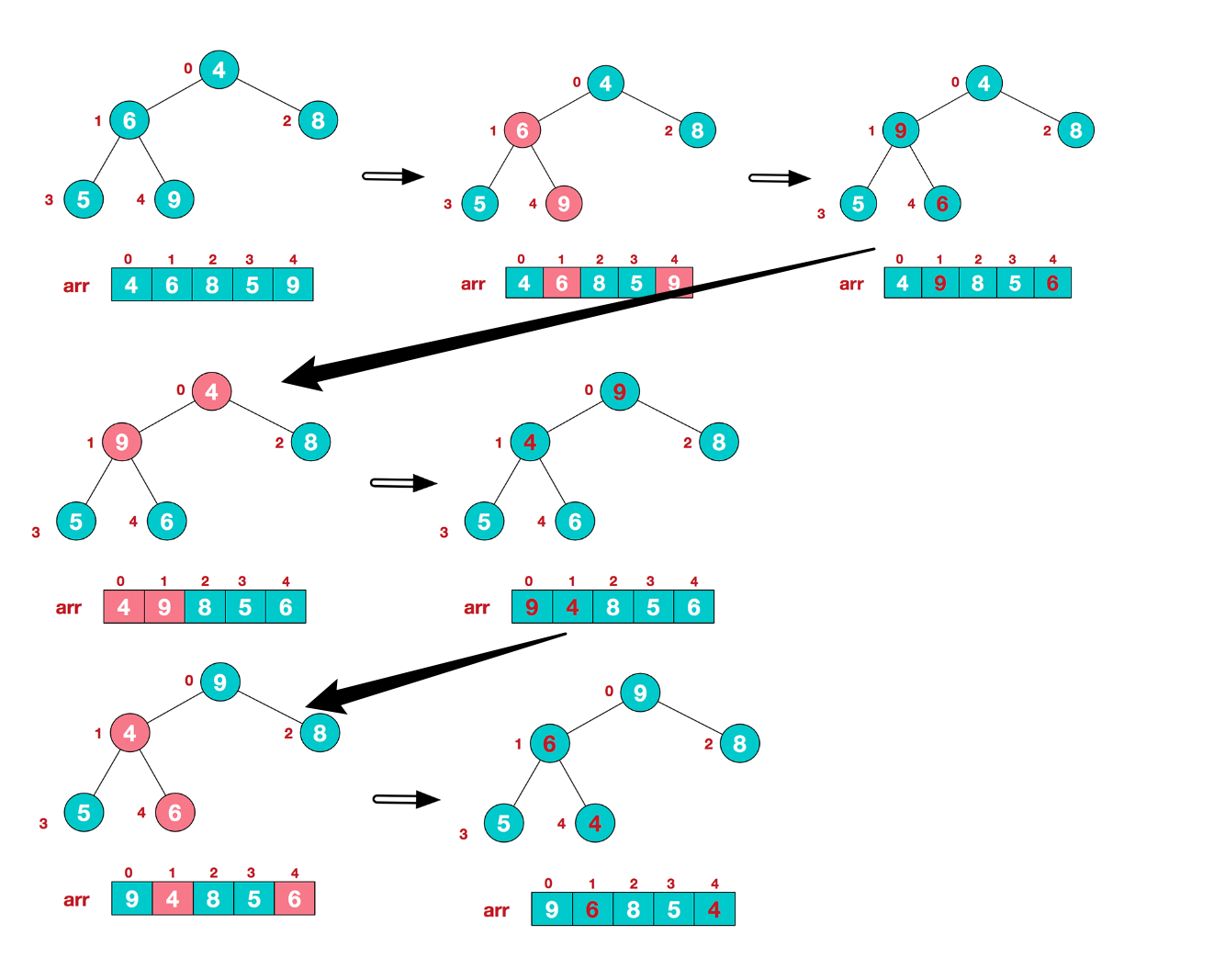
如果我们需要数组元素单调递减,需要最终形成一个大顶堆:从下往上倒序遍历非叶子结点(没有儿子节点的节点),通过交换方式依次调整父子结点顺序,直至符合大顶堆的规则。
举例:有如图的一个数组,需要这样操作便可得到一个有序的数组。
复杂度/稳定性分析
时间复杂度
和选择排序类似,总共需要操作 n 个数,不同的是,选择排序操作一个数需要 n ,而堆排序查找一个数只需要 log2n ,所以堆排序的时间复杂度是 O(nlog2n)
稳定性
堆排序和选择排序类似,排序过程中相同元素位置发生改变,不稳定。
代码实现
以下是c++实现,请参考注释理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| const int N = 1e4+5;
int m, a[N]
void adjust(int i, int parent)
{
int child = parent * 2;
if(child + 1 <= i && a[child] < a[child + 1]){
child++;
}
if(a[child] > a[parent]){
swap(a[child], a[parent]);
if(child <= i / 2){
adjust(i, child);
}
}
}
void heapSort(){
for(int i = n; i > 1; i--){
for(int j = i / 2; j >= 1; j--){
adjust(i, j);
}
swap(a[1], a[i]);
}
}
signed main(){
heapSort();
return 0;
}
|